首先声明,这篇文章包含不少公式。如果看的中途感到劳累了,请休息会,点杯coffee。当然,人生苦短,大可以放弃阅读传统算法,投入深度学习的怀抱吧。
Problem Formulation
日常通话过程中,到达麦克风的信号除了语音信号 $x(t)$ ,往往还有噪声信号 $n(t)$ ,因此麦克风输出的信号 $y(t)$ 就包含了两个部分,语音和噪声(这里不考虑混响的情况,而且认为噪声是加性噪声): $$ y(t) = x(t)+n(t) \tag{1} $$ 噪声抑制要做的就是从麦克风信号中抑制噪声信号 $n(t)$ ,保留干净语音信号 $x(t)$。一般而言我们会使用 STFT 将信号搬移到时频域来进行噪声的抑制: $$ Y(t,f) = X(t,f)+N(t,f)\tag{2} $$ 其中 $t$ 代表帧,$f$ 代表 frequency bin。
Prior & Posterior SNR
传统噪声抑制最为关键的两个要素是:先验信噪比 $\xi(t,f)$ 和后验信噪比 $\gamma(t,f)$。计算方式如下: $$ \xi(t,f) = \frac{|X(t,f)|^2}{|N(t,f)|^2} \tag{3} $$
$$ \gamma(t,f) = \frac{|Y(t,f)|^2}{|N(t,f)|^2} \tag{4} $$
这两个信噪比可以将大部分传统的算法联系起来,形成一个统一的框架,所以在这里先为介绍。
先验信噪比描述了干净语音功率和噪声功率之间的关系。后验信噪比则描述了带噪语音功率和噪声功率之间的关系。如果可以精确地估计这两个信噪比,就可以很好地对噪声进行抑制,所以传统算法基本围绕这两个信噪比的估计展开。
值得注意的是,公式 $(3),(4)$ 都需要计算噪声的功率 $|N(t,f)|^2$,处理这个问题的方法是:噪声估计。
另一个注意点,公式 $(3)$ 要求计算语音信号的功率 $|X(t,f)|^2$ (但一般不直接求取),处理这个问题的方法是:判决引导法 (DDA)。
Noise Estimation
首先处理噪声估计的问题。传统算法下噪声估计有三种重要思想:
- 噪声能量比较平稳,而且带语音的片段能量高于纯噪声的片段,所以可以通过跟踪功率最小值来获取噪声估计。
- 噪声功率估计想要稳定,通常要对功率谱进行平滑处理,也就是进行递归平均。
- 结合语音存在和不存在的概率,调节噪声估计在语音存在/不存在时各自的权重。
这三种思想各自都有对应的算法,在这里只介绍集合了三种思想的最小值控制的递归平均 (minima controlled recursive averaging, MCRA) 算法。
MCRA
针对3,MCRA算法将噪声估计划分为了两类:
$$ \begin{align} speech\ absent:& |N(t+1,f)|^2_{sa} = \alpha |N(t,f)|^2 + (1-\alpha)|Y(t,f)|^2 \tag{5} \\ speech\ present:& |N(t+1,f)|^2_{sp} = |N(t,f)|^2\tag{6} \end{align} $$
第一个式子代表语音不存在的时候,此时需要对噪声进行重新的估计,同时针对2使用了递归平均来稳定噪声的估计。
第二个式子代表语音存在的时候,因为此时语音存在,所以噪声延续上一帧的估计。
针对3,设定一个语音存在概率 $p(t,f)$ 作为权重来将噪声估计的式子写为一个: $$ |N(t+1,f)|^2 = p(t,f)\times |N(t+1,f)|^2_{sp} + (1-p(t,f))\times |N(t,f)|^2_{sa} \tag{7} $$ 此时需要对语音存在概率 $p(t,f)$ 进行估计, $$ p(t+1,f) = \alpha_p p(t,f)+(1-\alpha_p)\delta [S_r(t,f)-\Delta] \tag{8} $$ 上式使用了针对2的递归平均来计算,以稳定对于语音存在概率的估计,其中 $\delta[\cdot]$ 代表指示函数。$S_r(t,f)$ 的计算公式如下: $$ S_r(t,f) = \frac{\sum_{i=-n}^{n}{w(i)|Y(t,f+i)|^2}}{min [\sum_{i=-n}^{n}{w(i)|Y(t-1,f+i)|^2},\sum_{i=-n}^{n}{w(i)|Y(t,f+i)|^2}]}\tag{9} $$ 上式分号的上半部分 $\sum_{i=-n}^{n}{w(i)|Y(t,k+i)|^2}$ 代表对邻近频率点进行功率的平均,下半部分 $min[\cdot]$ 则代表不断获取局部的最小功率。整个式子的含义在于求得当前帧的功率与局部帧的最小功率的比值 $S_r(t,f)$ ,如果这个比值大于 $\Delta$ ,那么就可以认为当前帧的能量是比较高的,需要用来更新对于语音存在概率的估计。这种想法来源于针对1的最小值功率的跟踪。
Summary
整个MCRA算法是比较简单的,思路在于先通过 $(8),(9)$ 求取语音存在概率 $p(t,f)$ ,然后就可以根据 $(7)$ 来进行噪声的估计了。
Prior SNR Estimation
通过对噪声功率的估计获取了 $|N(t,f)|^2$ ,同时带噪语音的功率 $|Y(t,f)|^2$ 也可以直接获取。因此根据 $(4)$ 可以得到后验信噪比 $\gamma(t,f)$ 的估计。但先验信噪比应该如何估计呢?
不妨大胆一点,我们假设噪声和语音是不相关的,可以得到: $$ \begin{align} |Y(t,f)|^2 &= Y(t,f) \times Y^*(t,f) \tag{10}\\ &= [X(t,f)+N(t,f)] \times [X(t,f)+N(t,f)]^{\star} \tag{11}\\ &= |X(t,f)|^2 +|N(t,f)|^2\tag{12} \end{align} $$ 这样,我们就可以得到干净语音的功率估计为: $$ |X(t,f)|^2 = |Y(t,f)|^2 - |N(t,f)|^2 \tag{13} $$ 此时就可以通过 $(3)$ 来计算先验信噪比了。当然,我们还可以获得先验信噪比和后验信噪比的关系式: $$ \xi(t,f) = \frac{|Y(t,f)|^2-|N(t,f)|^2}{|N(t,f)|^2}= \gamma(t,f)-1 \tag{14} $$ 需要注意到,理论上分析有 $|Y(t,f)|^2 \ge |N(t,f)|^2$ ,可是 $|N(t,f)|^2$ 是通过噪声估计得到的,存在大于 $|Y(t,f)|^2$ 的可能性,所以通过后验信噪比来估计先验信噪比还需要加入 $max[\cdot]$ 函数来保证非负: $$ \xi(t,f) =max[\gamma(t,f)-1, 0] \tag{15} $$
DDA
但是,实际中一般会采取DDA来实现更加精确的估计: $$ \xi(t,f) = \alpha \xi(t-1,f) + (1-\alpha)max[\gamma(t,f)-1,0] \tag{16} $$ 注意到上式其实就是一个递归平均,第一项 $\xi(t-1,f)$ 为前一帧估计的先验信噪比,第二项 $max[\gamma(t,f)-1,0]$ 是当前帧估计的先验信噪比。
Summary
对于先验信噪比的估计核心之一在于求得后验信噪比 $\gamma(t,f)$ ,而后验信噪比本质上又和噪声估计息息相关。所以对于噪声的估计是传统里需要着重处理的问题。(但是,似乎在神经网络部分很少见到有人尝试对噪声进行估计了,可能因为估计难度比较高?)
Noise Suppression
前面介绍了先验信噪比和后验信噪比的定义及其求法,但可能你还云里雾里不清楚为什么需要求这两个信噪比,而在这里我将通过几个经典的噪声抑制算法向你展示其美妙之处。
1. Spectral Subtraction
顾名思义,谱减法就是从带噪语音功率谱减去噪声功率谱,得到干净语音的功率谱。那么会有下面的式子: $$ \begin{align} |X(t,f)|^2 &= |Y(t,f)|^2-|N(t,f)|^2 \tag{17} \\ &= [1-\frac{1}{\gamma(t,f)}]\times |Y(t,f)|^2 \tag{18} \end{align} $$ 所以,只需要求得后验信噪比 $\gamma(t,f)$ 就可以实现谱减法了。
2. Wiener Filter
维纳滤波只做一件事:实现真实信号 $X(t,f)$ 与估计信号 $\hat X(t,f)$ 的均方误差最小。而噪声抑制的方式是通过计算滤波器实现滤波: $$ \hat X(t,f) = H(t,f)Y(t,f) \tag{19} $$ 均方误差最小的优化式子为: $$ \begin{align} min\ J =& E {(X(t,f)-\hat X(t,f))(X(t,f)-\hat X(t,f))^* } \tag{20}\\ =& |X(t,f)|^2+|H(t,f)|^2|Y(t,f)|^2 \\ &-X(t,f)H^{\star}(t,f)Y^{\star}(t,f) - X^{\star}(t,f)H(t,f)Y(t,f) \tag{21} \end{align} $$ 然后求梯度,找到最小值: $$ \nabla J_{H(t,f)} = 2H(t,f)|Y(t,f)|^2 - X(t,f)Y^{\star}(t,f)-X^{\star}(t,f)Y(t,f)=0 \tag{22} $$ 上式可以得到: $$ \begin{align} H(t,f) &= \frac{X(t,f)Y^{\star}(t,f)}{|Y(t,f)|^2} \tag{23}\\ &= \frac{X(t,f)(X^{\star}(t,f)+N^{\star}(t,f))}{|X(t,f)|^2+|N(t,f)|^2}\tag{24}\\ &= \frac{|X(t,f)|^2}{|X(t,f)|^2+|N(t,f)|^2}\tag{25}\\ &= \frac{\xi(t,f)}{1+\xi(t,f)}\tag{26} \end{align} $$ 注意上式 $(23)\rightarrow(24)$ 使用了噪声和语音不相关的特性来得到分号下边,$(24)\rightarrow(25)$ 同样使用了噪声和语音不相关特性来使得 $X(t,f)N^{\star}(t,f)=0$ 。那么整个维纳滤波就可以转化为下式: $$ \begin{align} X(t,f) &= H(t,f)Y(t,f)\tag{27}\\ &= \frac{\xi(t,f)}{1+\xi(t,f)}Y(t,f)\tag{28} \end{align} $$ 所以,只需要求得先验信噪比 $\xi(t,f)$ 就可以实现维纳滤波了。(另一个有意思的点是,维纳滤波是复数谱上的估计,而不仅仅是幅度谱。)
3. Statistic-Based Model
这一类方法一律依赖贝叶斯准则: $$ P(X|Y) = \frac{P(Y|X)P(X)}{P(Y)}\tag{29} $$ 上式中 $P(X|Y)$ 称为后验, $P(Y|X)$ 称为似然, $P(X)$ 称为先验,$P(Y)$ 称为证据。当最大化后验概率的时候称之为 MAP ,最大化似然的时候称之为 MLE。这一类估计需要复杂的数学推理,在这里就不进行了。
但是,同样地其噪声抑制的表达式仍旧可以写为(以下以 MLE 为例子): $$ |X(t,f)| = [ \frac{1}{2}+\frac{1}{2}\sqrt{\frac{\xi_(t,f)}{1+\xi(t,f)}} ]|Y(t,f)|\tag{30} $$ 可以看到,仍旧可以通过计算 $\xi(t,f)$ 先验信噪比来实现噪声抑制。
OMLSA
基于统计学方法的最为出名的,可能还得是 OMLSA 算法了,其结合了两种思想:log-MMSE 最优估计器和语音存在概率。其增益函数的表达式如下: $$ \begin{align} speech\ absent:&G_{sa}(t,f) = G_{min}(t,f) \tag{31}\\ speech\ present:&G_{sp}(t,f) = \frac{\xi(t,f)}{1+\xi(t,f)}\int_{v(t,f)}^{\infty}\frac{1}{2}\frac{e^{-t}}{t}dt \tag{32} \end{align} $$ 其中 $v(t,f) = \frac{\xi(t,f)\gamma(t,f)}{1+\xi(t,f)}$。
与 MCRA 算法一致的,两者都需要估计语音存在概率 $p(t,f)$,通过语音存在概率可以将整个增益式子写为: $$ G(t,f) = G_{sp}(t,f)^{p(t,f)}\times G_{sa}(t,f)^{1-p(t,f)} \tag{33} $$ 与 MCRA 算法不一致的是,两者估计语音存在概率 $p(t,f)$ 的方式不一样,OMLSA 采取的估计方式为: $$ p(t,f) = [1+\frac{q(t,f)}{1-q(t,f)}\times(1+\xi(t,f))\times e^{-v(t,f)}]^{-1} \tag{34} $$ 其中 $q(t,f)$ 为语音缺失概率,也就是将语音存在概率通过 $(34)$ 转化为了求解语音缺失概率。语音缺失概率计算公式为: $$ q(t,f) = 1-p_{local}(t,f)\times p_{global}(t,f)\times p_{frame}(t,f) \tag{35} $$ 将求解转化为了三个语音存在概率 $p_{local}(t,f), p_{global}(t,f), p_{frame}(t,f)$ 进行计算。(真是绕的不行= =,具体这三个概率的计算见论文)
summary
OMLSA 的增益函数的计算方式其实就两个关键:logMMSE 最优估计器和语音存在概率。
在计算的时候需要首先通过计算语音缺失概率 $q(t,f)$ ,然后得到语音存在概率 $p(t,f)$ ,接着通过 $(31),(32),(33)$ 来计算增益式子。
值得注意的是增益式子同样是由先验信噪比 $\xi(t,f)$ 和后验信噪比 $\gamma(t,f)$ 构成的。
MCRA-OMLSA
由 cohen 提出的 MCRA-OMLSA 是一个非常经典的噪声抑制算法。其将语音存在概率分别用于噪声估计和增益函数的求解,使得能够在非稳态噪声的情况下也取得不错的性能。算法很简单,其实就是结合了OMLSA和MCRA,而在前面已经对两个算法进行介绍了,所以这里只给出一个流程框图:
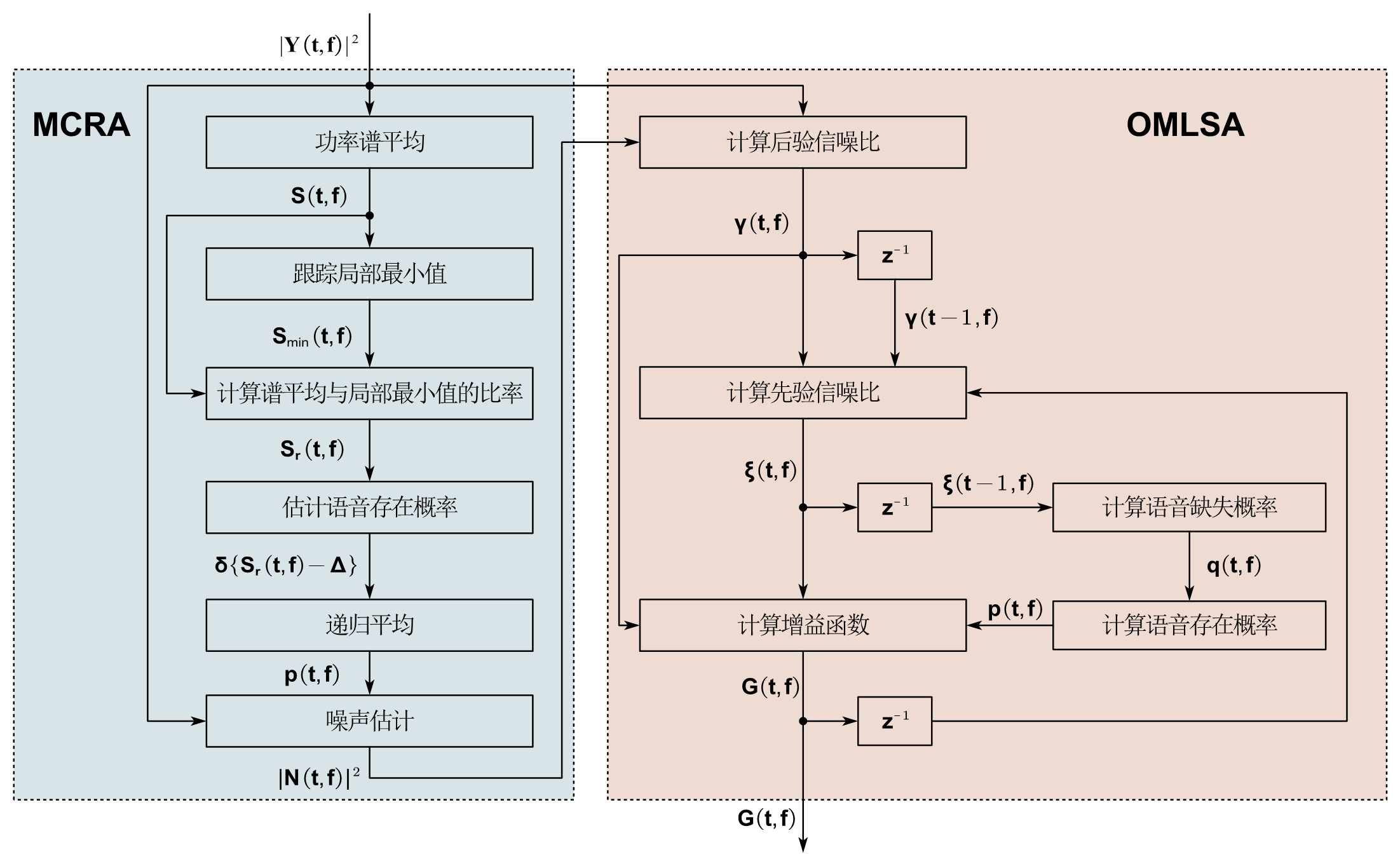
上图忽略了一些计算的细节(尤其是语音缺失和语音存在概率的计算细节),但是大致上是按照这个流程走的。
Traditional VS Deep-Learning
Traditional
就目前学习到的传统算法而言,都是基于下面的式子的: $$ |X(t,f)| = G(t,f)|Y(t,f)| \tag{36} $$ 总体而言就是求解一个增益函数 $G(t,f)$ 来对幅度谱进行增强。
这样做存在的问题:
- 无法对相位进行增强(大部分)
- 对于噪声估计的要求十分苛刻,因为先验信噪比和后验信噪比的估计都离不开噪声估计
这样做带来的优点:
- 不同于神经网络,这样做只需要很少,或者几乎没有参数的存储要求
- 不同于神经网络,这样做运算量小了非常多
Deep-Learning
传统方法与深度学习的噪声抑制存在非常强的关联性。深度学习的噪声抑制式子为(下式仅考虑了幅度): $$ |X(t,f)|=M(t,f)|Y(t,f)| \tag{37} $$ 显然可以看到,深度学习中的掩膜 $M(t,f)$ (Mask) 实际上就是传统方法中的增益 $G(t,f)$ (Gain) 函数。
而深度学习优势在于:
- 可以将相位也考虑进网络的优化,使得掩膜变为复数掩膜,带来相比于传统算法更好的性能
- 不再需要使用复杂的算法来估计噪声,先验,后验信噪比
- 可以通过让网络来自行学习如何估计掩膜(也就是增益,但带来的就是对于训练数据的要求)
- 能够处理更加复杂的噪声情况
同时深度学习的缺点在于:
- 运算量较大
- 参数量较大
Summary
总体而言,传统的噪声抑制算法存在比较多的数学和工程知识,而且需要不少假设来简化理论推导。但是带来的是低复杂度,还有不错的效果。当然,由于对噪声估计的依赖,个人认为在使用神经网络去除部分噪声之后,将传统算法作为postfilter可能会是一个不错的选择。因为在通过神经网络消除部分噪声之后,可以尽可能保证带语音的片段能量高于纯噪声的片段,来满足噪声估计的要求。
在神经网络大行其道的如今,传统算法并不是不能发挥其作用。工程中,综合考虑运算复杂度和性能时,结合轻量化的神经网络和传统算法可能会是一个较好的选择。